Stream
- sequence of elements: 一个流对外提供一个接口,可以访问到一串特定的数据。流不存储元素,但是可以根据需要进行计算转化
- source:数据来源,如数据结构,数组,文件等
- aggregate operation:聚合操作,流支持像SQL操作或者其他函数式语言的操作,如filter/map/reduce/find/match/sorted等
- Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
- Internal Iteration: 以前对集合遍历都是通过Iterator或者增强for的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式,流可以直接调用遍历方法。
处理流程
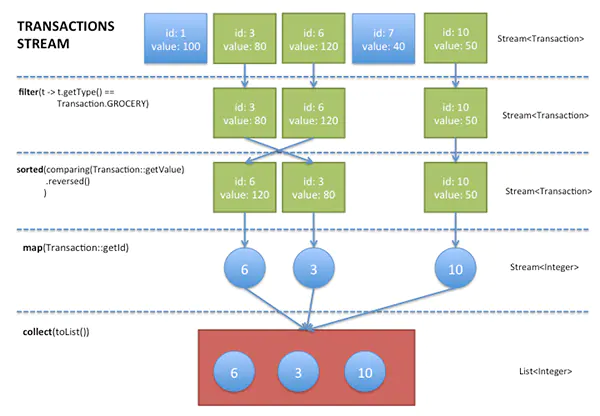
- 流的创建
- 流的转换,将流转换为其他流的中间操作,可包括多个步骤(惰性操作)
- 流的计算结果。这个操作会强制执行之前的惰性操作。这个步骤以后,流就再也不用了
获取流
Stream类
- of 方法,直接将数组转化
Stream<Integer> integerStream = Stream.of(1, 2, 3);
- empty方法,产生一个空流
- generate 方法,接收一个Lambda表达式
Stream<Double> stream = Stream.generate(Math::random);
- iterate方法,接收一个种子,和一个Lambda表达式
Stream<BigInteger> iterate = Stream.iterate(BigInteger.ZERO, n -> n.add(BigInteger.ONE));
根据Collection获取
Stream<String> stream = list.stream();
根据Map获取流
Stream<String> keyStream = map.keySet().stream();
Stream<String> valueStream = map.values().stream();
Stream<Map.Entry<String, String>> entryStream = map.entrySet().stream();
基本类型流
- IntStream,LongStream,DoubleStream
并行流
- 使得所有的中间转换操作都将被并行化
- Collections.parallelStream()将任何集合转为并行流
- Stream.parallel()方法,产生一个并行流
流的方法
- 延迟方法(中间操作):返回值类型仍然是 Stream 接口自身类型的方法,因此支持链式调用。(除了终结方法外,其余方 法均为延迟方法。)
- 终结方法(结束操作):返回值类型不再是 Stream 接口自身类型的方法,因此不再支持类似 StringBuilder 那样的链式调用。
| 操作类型 | 接口方法 |
|---|---|
| 中间操作 | concat() distinct() filter() flatMap() limit() map() peek() skip() sorted() parallel() sequential() unordered() |
| 结束操作 | allMatch() anyMatch() collect() count() findAny() findFirst() forEach() forEachOrdered() max() min() noneMatch() reduce() toArray() |
转换方法
过滤filter
- filter(Predicate<? super T> predicate)
- 接收一个Lambda表达式,对每个元素进行判定,符合条件留下
去重distinct
- 对流的元素进行过滤,去除重复,只留下不重复的元素
- 对象的判定,先调用hashCode方法,再调用equals方法
排序sorted
- 提供Comparator,对流的元素进行排序
map
利用方法引用对流每个元素进行函数计算
Stream.of(1,2,3)
.map(String::valueOf)
.forEach(System.out::println); // ["1","2","3"]
flatMap
对结果进行展开
抽取limit
只取前n个
跳过skip
跳过前n个
连接concat
Stream.concat(s1,s2); // 连接两个流
额外调试peek
可以对流操作,但是不影响它
Optional
Optional<T>
- 一个包装器对象
- 要么包装了类型T的对象,要么没有包装任何对象
- 如果T有值,那么直接返回T的对象
- 如果T是null,那么可以返回一个替代物
使用
- get方法,获取值,不安全的用法
- orElse方法,获取值,如果为null,采用替代物的值
- orElseGet方法,获取值,如果为null,采用Lambda表达式值返回
- orElseThrow方法,获取值,如果为null,抛出异常
- ifPresent方法,判断是否为空,不为空返回true
- isPresent(Consumer), 判断是否为空,如果不为空,则进行后续Consumer操作,如果为空,则不做任何事情
- map(Function), 将值传递给Function函数进行计算。如果为空,则不计算
注意事项
- 直接使用get,很容易引发NoSuchElementException异常
- 使用isPresent判断值是否存在,这和判断null是一样的低效
终结方法
聚合函数
- count(), 计数
- max(Comparator),最大值,需要比较器
- min(Comparator),最小值,需要比较器
- findFirst(), 找到第一个元素
- findAny(), 找到任意一个元素
- anyMatch(Predicate),如有任意一个元素满足Predicate,返回true
- allMatch(Predicate),如所有元素满足Predicate,返回true
- noneMatch(Predicate),如没有任何元素满足Predicate,返回true
归约函数
reduce,传递一个二元函数BinaryOperator,对流元素进行计算
如求和、求积、字符串连接
// 求单词长度之和
Stream<String> stream = Stream.of("I", "love", "you", "too");
Integer lengthSum = stream.reduce(0, // 初始值 // (1)
(sum, str) -> sum+str.length(), // 累加器 // (2)
(a, b) -> a+b); // 部分和拼接器,并行执行时才会用到 // (3)
// int lengthSum = stream.mapToInt(str -> str.length()).sum();
System.out.println(lengthSum);
collect方法
// 将Stream转换成容器或Map
Stream<String> stream = Stream.of("I", "love", "you", "too");
List<String> list = stream.collect(Collectors.toList()); // (1)
// Set<String> set = stream.collect(Collectors.toSet()); // (2)
// Map<String, Integer> map = stream.collect(Collectors.toMap(Function.identity(), String::length)); // (3)
迭代函数
- iterator() :获取一个迭代器
- forEach(Consumer),应用一个函数到每个元素上
收集函数
- toArray(),将结果转为数组
- collect(Collectors.toList()),将结果转为List
- collect(Collectors.toSet()),将结果转为Set
- collect(Collectors.toMap()), 将结果转为Map
- collect(Collectors.joining()), 将结果连接起来
优点
- 统一转换元素
- 过滤元素
- 利用单个操作合并元素
- 将元素序列存放到某一个集合中
- 搜索满足某些条件的元素的序列
- 类似SQL操作,遵循“做什么而非怎么做”原则
- 简化了串行/并行的大批量操作
- stream上的操作并不会立即执行,只有等到用户真正需要结果的时候才会执行
与循环迭代比较
- Stream广泛使用Lambda表达式,只能读取外围的final或者effectivelyfinal变量,循环迭代代码可以读取/修改任意的局部变量
- 在循环迭代代码块中,可以随意break/continue/return,或者抛出异常,而Lambda表达式无法完成这些事情
注意事项
- 一个流,一次只能一个用途,不能多个用途,用了不能再用
- Stream只是某种数据源的一个视图
- 避免创建无限流
- 注意操作顺序
- 谨慎使用并行流
Stream流水线原理
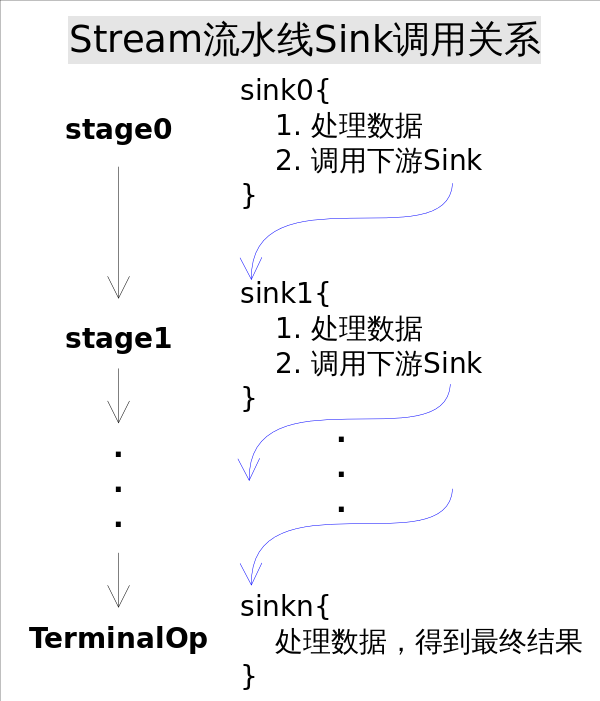
parallelStream 通过默认的ForkJoinPool,可能提高多线程任务的速度
多个parallelStream之间默认使用的是同一个线程池