编译原理
词法解析
// JavaParser
public JCTree.JCCompilationUnit parseCompilationUnit() {
Token firstToken = token;
JCModifiers mods = null;
boolean consumedToplevelDoc = false;
boolean seenImport = false;
boolean seenPackage = false;
ListBuffer<JCTree> defs = new ListBuffer<>();
if (token.kind == MONKEYS_AT)
mods = modifiersOpt(); // 解析修饰符
if (token.kind == PACKAGE) { // 解析包声明
int packagePos = token.pos;
List<JCAnnotation> annotations = List.nil();
seenPackage = true;
if (mods != null) {
checkNoMods(mods.flags);
annotations = mods.annotations;
mods = null;
}
nextToken();
JCExpression pid = qualident(false);
accept(SEMI);
JCPackageDecl pd = toP(F.at(packagePos).PackageDecl(annotations, pid));
attach(pd, firstToken.comment(CommentStyle.JAVADOC));
consumedToplevelDoc = true;
defs.append(pd);
}
boolean checkForImports = true;
boolean firstTypeDecl = true;
while (token.kind != EOF) {
if (token.pos <= endPosTable.errorEndPos) {
// error recovery
skip(checkForImports, false, false, false);
if (token.kind == EOF)
break;
}
if (checkForImports && mods == null && token.kind == IMPORT) { // 解析import
seenImport = true;
defs.append(importDeclaration());
} else { // 解析类主体
Comment docComment = token.comment(CommentStyle.JAVADOC); // 类doc注释
if (firstTypeDecl && !seenImport && !seenPackage) {
docComment = firstToken.comment(CommentStyle.JAVADOC);
consumedToplevelDoc = true;
}
if (mods != null || token.kind != SEMI)
mods = modifiersOpt(mods);
if (firstTypeDecl && token.kind == IDENTIFIER) {
ModuleKind kind = ModuleKind.STRONG; // 模块解析
if (token.name() == names.open) {
kind = ModuleKind.OPEN;
nextToken();
}
if (token.kind == IDENTIFIER && token.name() == names.module) {
if (mods != null) {
checkNoMods(mods.flags & ~Flags.DEPRECATED);
}
defs.append(moduleDecl(mods, kind, docComment));
consumedToplevelDoc = true;
break;
} else if (kind != ModuleKind.STRONG) {
reportSyntaxError(token.pos, Errors.ExpectedModule);
}
}
JCTree def = typeDeclaration(mods, docComment);
if (def instanceof JCExpressionStatement)
def = ((JCExpressionStatement)def).expr;
defs.append(def);
if (def instanceof JCClassDecl)
checkForImports = false;
mods = null;
firstTypeDecl = false;
}
}
JCTree.JCCompilationUnit toplevel = F.at(firstToken.pos).TopLevel(defs.toList());
if (!consumedToplevelDoc)
attach(toplevel, firstToken.comment(CommentStyle.JAVADOC));
if (defs.isEmpty())
storeEnd(toplevel, S.prevToken().endPos);
if (keepDocComments)
toplevel.docComments = docComments;
if (keepLineMap)
toplevel.lineMap = S.getLineMap();
this.endPosTable.setParser(null); // remove reference to parser
toplevel.endPositions = this.endPosTable;
return toplevel;
}
JavaParser 根据 Java 语言规范来解析.java文件进行词法解析
每调用一次nextToken 就会构造一个Token
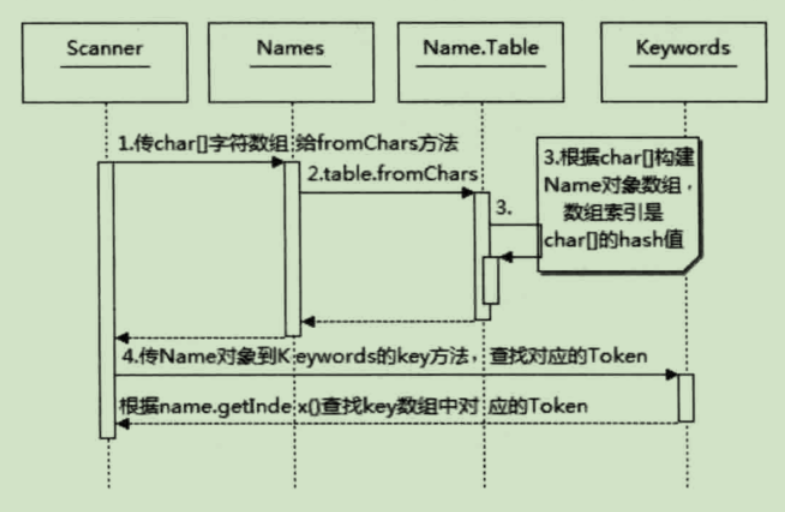
语法分析
- 进行package词法分析的时候构建一个节点
JCExpression t = toP(F.at(token.pos).Ident(ident()));
- 进行import词法分析时构造的import语法树
protected JCTree importDeclaration() {
int pos = token.pos;
nextToken();
boolean importStatic = false;
if (token.kind == STATIC) {
importStatic = true;
nextToken();
}
JCExpression pid = toP(F.at(token.pos).Ident(ident()));
do {
int pos1 = token.pos;
accept(DOT);
if (token.kind == STAR) {
pid = to(F.at(pos1).Select(pid, names.asterisk));
nextToken();
break;
} else {
pid = toP(F.at(pos1).Select(pid, ident()));
}
} while (token.kind == DOT);
accept(SEMI);
return toP(F.at(pos).Import(pid, importStatic));
}
- 类主体语法树构造
JCTree typeDeclaration(JCModifiers mods, Comment docComment) {
int pos = token.pos;
if (mods == null && token.kind == SEMI) {
nextToken();
return toP(F.at(pos).Skip());
} else {
return classOrRecordOrInterfaceOrEnumDeclaration(modifiersOpt(mods), docComment);
}
}
最后会生成一颗完整的语法树
语义分析
打磨语法树
- Enter类
代码生成
- Gen类