Linux性能优化
CPU
系统层面的一些优化手段:
- CPU 绑定:把进程绑定到一个或者多个 CPU 上,可以提高 CPU 缓存的命中率,减少跨 CPU 调度带来的上下文切换问题
- CPU 独占:跟 CPU 绑定类似,进一步将 CPU 分组,并通过 CPU 亲和性机制为其分配进程。这样,这些 CPU 就由指定的进程独占,换句话说,不允许其他进程再来使用这些 CPU
- 优先级调整:使用 nice 调整进程的优先级,正值调低优先级,负值调高优先级。,适当降低非核心应用的优先级,增高核心应用的优先级,可以确保核心应用得到优先处理
- 为进程设置资源限制:使用 Linux cgroups 来设置进程的 CPU 使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源
- NUMA(Non-Uniform Memory Access)优化:支持 NUMA 的处理器会被划分为多个 node,每个 node 都有自己的本地内存空间。NUMA 优化,其实就是让 CPU 尽可能只访问本地内存
- 中断负载均衡:无论是软中断还是硬中断,它们的中断处理程序都可能会耗费大量的 CPU。开启 irqbalance 服务或者配置 smp_affinity,就可以把中断处理过程自动负载均衡到多个 CPU 上。
平均负载
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,和 CPU 使用率并没有直接关系
在只有 2 个 CPU 的系统上,平均负载为 2 代表所有的 CPU 都刚好被完全占用,大量 IO 会导致平均负载变高,但 CPU 使用率却不一定高
top 命令展示的三个值,分别为 1 分钟、5 分钟、15 分钟内的平均负载
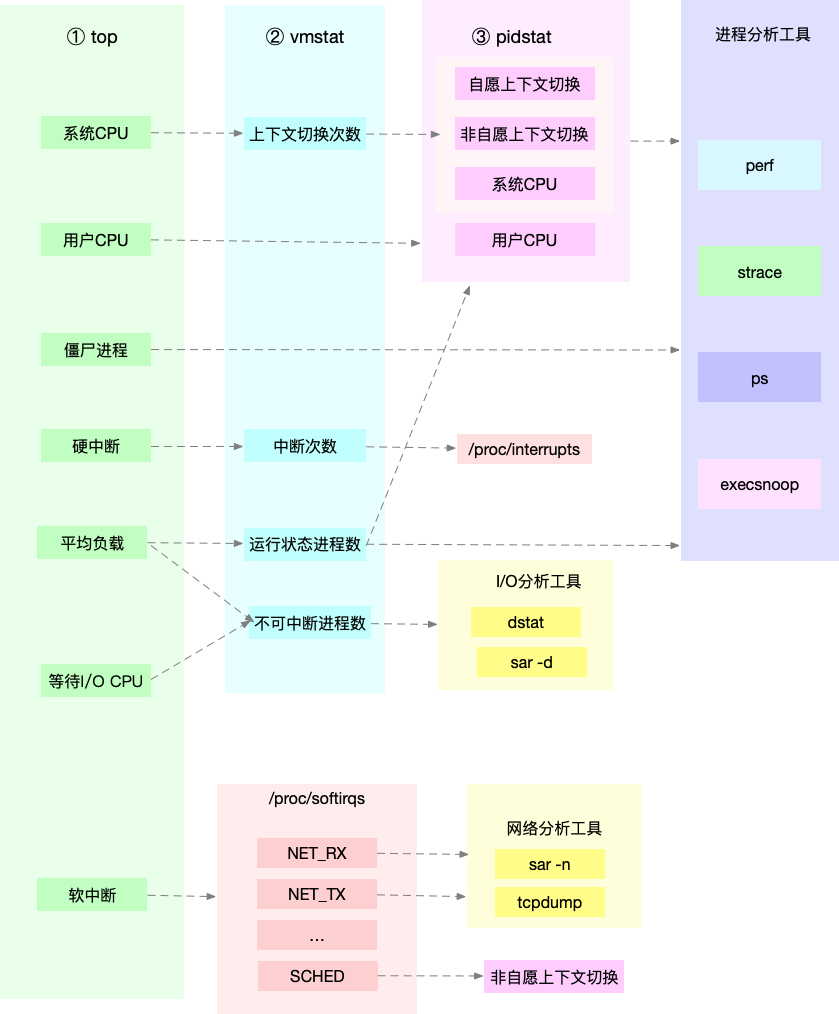
上下文切换
vmstat 可以查看系统整体上下文切换情况:
- cs(context switch)是每秒上下文切换的次数
- in(interrupt)则是每秒中断的次数
- r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数
- b(Blocked)则是处于不可中断睡眠状态的进程数
pidstat 则可以查看单个进程的上下文切换情况,cswch ,表示每秒自愿上下文切换(voluntary context switches)的次数,另一个则是 nvcswch ,表示每秒非自愿上下文切换(non voluntary context switches)的次数
- 自愿上下文切换:是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。
- 非自愿上下文切换:是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换
中断处理也需要上下文切换,可以通过 /proc/interrupts 查看中断最多的类型
CPU使用率
通过 top 可以查看 CPU 在不同场景下的运行时间:
- user(通常缩写为 us),代表用户态 CPU 时间。注它不包括下面的 nice 时间,但包括了 guest 时间
- nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低
- system(通常缩写为 sys),代表内核态 CPU 时间
- idle(通常缩写为 id),代表空闲时间。它不包括等待 I/O 的时间(iowait)
- iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间
- irq(通常缩写为 hi),代表处理硬中断的 CPU 时间
- softirq(通常缩写为 si),代表处理软中断的 CPU 时间
- steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间
- guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间
- guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间
为了在具体进程找到占用 CPU 时钟最多的函数或者指令,可以通过 perf top 查看函数名或函数地址
软中断
Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部:
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行
网卡接收到数据包后,会通过硬件中断的方式通知内核有新的数据到了 对上半部来说,既然是快速处理,其实就是要把网卡的数据读到内存中,然后更新一下硬件寄存器的状态(表示数据已经读好了),最后再发送一个软中断信号,通知下半部做进一步的处理 下半部被软中断信号唤醒后,需要从内存中找到网络数据,再按照网络协议栈,对数据进行逐层解析和处理,直到把它送给应用程序
上半部会打断 CPU 正在执行的任务,然后立即执行中断处理程序。而下半部以内核线程的方式执行,并且每个 CPU 都对应一个软中断内核线程,名字为 “ksoftirqd/CPU 编号”
- /proc/softirqs 提供了软中断的运行情况
- /proc/interrupts 提供了硬中断的运行情况
当软中断事件的频率过高时,内核线程也会因为 CPU 使用率过高而导致软中断处理不及时,进而引发网络收发延迟、调度缓慢等性能问题