集合
集合是java中提供的一种容器,可以用来存储多个数据
类层次结构
mindmap
容器
Collection
List[List]
CopyOnWriteList
ArrayList
Vector
Stack
LinkedList
Set(Set)
HashSet
LinkedHashSet
SortedSet
TreeSet
CopyOnWriteArraySet
ConcurrentSkipListSet
Queue((Queue))
Deque{{Deque}}
ArrayDeque
BlockingDeque
LinkedBlockingDeque
BlockingQueue))BlockingQueue((
ArrayBlockingQueue
PriorityBlockingQueue
LinkedBlockingQueue
TransferQueue
LinkedTransferQueue
SynchronousQueue
PriorityQueue
ConcurrentLinkedQueue
DelayQueue
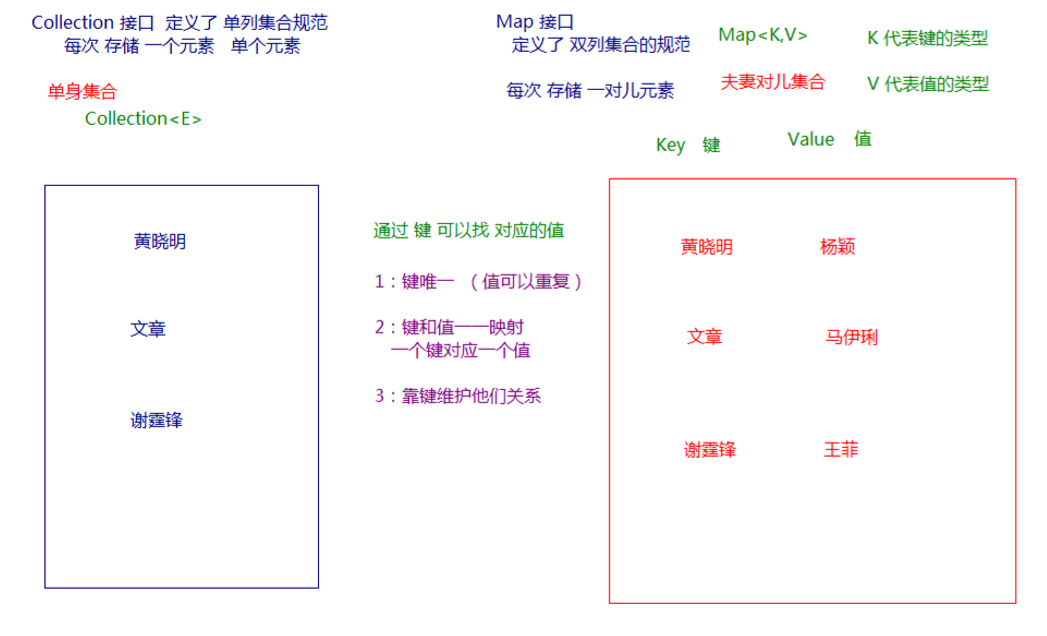
Map
HashMap
LinkedHashMap
TreeMap
WeakHashMap
IdentityHashMap
- List 存储一组不唯一(可以有多个元素引用相同的对象),有序的对象
- Set 不允许重复的集合。不会有多个元素引用相同的对象
- Queue 被设计用来可以以某种优先级处理元素的集合
- Map 使用键值对存储。Map会维护与Key有关联的值
可以学习人家的接口是怎么划分的,这个类虽然接口众多,但是职责却很清晰
以及人家是如何复用已有的代码来实现新功能
Iterator迭代器
Iterator<String> it = coll.iterator();
while(it.hasNext()){ //判断是否有迭代元素
String s = it.next();//获取迭代出的元素
System.out.println(s);
}
List
List 集合的遍历结果是稳定的
- ArrayList
- 非线程安全
- 内部使用数组
- 快速随机访问 插入删除慢
- LinkedList
- 本质双向链表
- 插入删除快 随机访问慢
- 内存利用率较高
常用方法
- public void add(int index, E element) : 将指定的元素,添加到该集合中的指定位置上。 -
- public E get(int index) :返回集合中指定位置的元素。
- public E remove(int index) : 移除列表中指定位置的元素, 返回的是被移除的元素。
- public E set(int index, E element) :用指定元素替换集合中指定位置的元素,返回值的更新前的元素
Queue
- FIFO
- 阻塞队列阻塞的特性与FIFO结合 适合做Buffer
Map集合
常用子类
| Map集合类 | Key | Value | Super | JDK | 说明 |
|---|---|---|---|---|---|
| Hashtable | 不允许为null | 不允许为null | Dictionary | 1.0 | 线程安全(过时) |
| ConcurrentHashMap | 不允许为null | 不允许为null | AbstractMap | 1.5 | 锁分段技术或CAS(JDK8及以上) |
| TreeMap | 不允许为null | 允许为null | AbstractMap | 1.2 | 线程不安全(有序) |
| HashMap | 允许为null | 允许为null | AbstractMap | 1.2 | 线程不安全( resize死链问题) |
在任何Map中 都要避免KV设置为null
- HashMap
并发场景下 数据丢失
死链问题:并发情况下链表修改导致的不一致问题
- ConcurrentHashMap
JDK11后取消了分段锁机制 引入了红黑树结构 put remove size等操作都是用了CAS
- LinkedHashMap
- TreeMap key有序 基于红黑树实现
并非一定要覆写hashCode与equals 其内部元素时通过Comparable与Comparator来实现key去重排序的
常用方法
- public V put(K key, V value) : 把指定的键与指定的值添加到Map集合中。
- public V remove(Object key) : 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的 值。
- public V get(Object key) 根据指定的键,在Map集合中获取对应的值。
- public Set
keySet() : 获取Map集合中所有的键,存储到Set集合中。 - public Set<Map.Entry<K,V>> entrySet() : 获取到Map集合中所有的键值对对象的集合(Set集合)。
Set集合
- 不允许出现重复
HashSet
底层使用hashmap
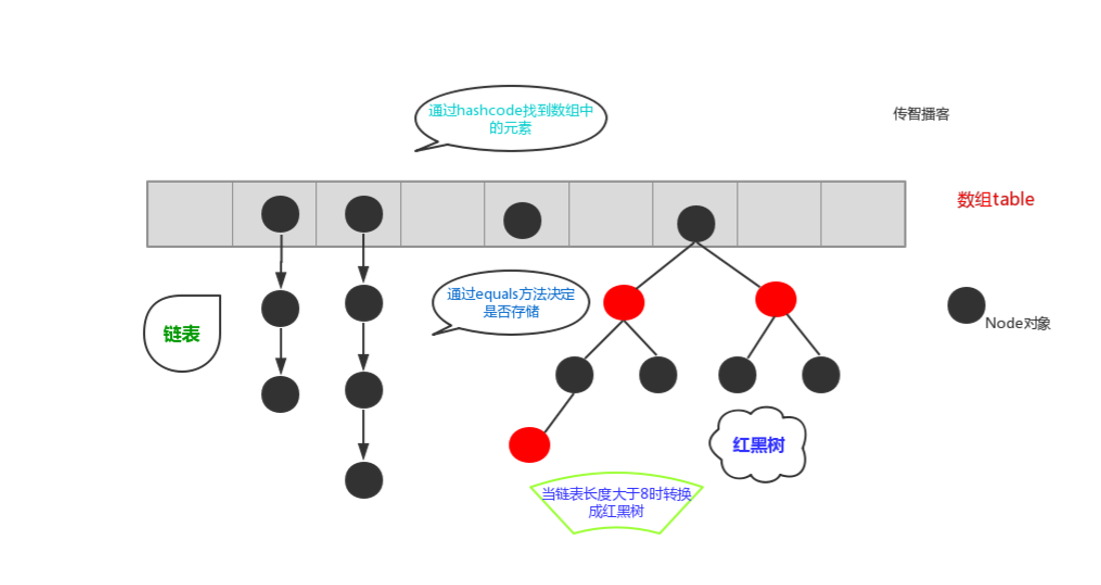
存储自定义类型元素时,需要重写对象中的hashCode和equals方法
TreeSet
底层使用TreeMap 保证Key有序
LinkedHashSet
有序的哈希集合
Collections 工具类
- public static
boolean addAll(Collection c, T... elements) :往集合中添加一些元素。 - public static void shuffle(List<?> list) 打乱顺序 :打乱集合顺序。
- public static
void sort(List list) :将集合中元素按照默认规则排序。 - public static
void sort(List list,Comparator<? super T> ) :将集合中元素按照指定规则排序
集合初始化
- ArrayList的初始值为10 每次扩容以1.5倍的速度进行扩容
- HashMap的初始值为16 每次扩容以2的幂进行扩容
这样如果存放在集合的元素比较多 就会造成不断扩容 影响性能
所以集合初始化时应该指定好默认值
数组与集合
new int[-1]; // 运行时异常:NegativeArraySizeException:-1
数组遍历优先使用foreach方式
数组转集合
注意转集合的过程中是否使用了视图的方式:
Arrays.asList(...)这个方法返回了一个不可变的ArrayList(Arrays的内部类),不能进行修改操作 否则会抛出异常
集合转数组
Object[] objects = list.toArray();// 泛型丢失
String[] arr1 = new String[2];
list.toArray(arr1); // arr1为[null,null]
String[] arr2 = new String[3];
list.toArray(arr2); // arr2为[1,2,3]
当toArray传入的数组容量比size小时 该方法就会弃用这个数组 而是自己创建一个数组返回
当数组容量等于size时 运行时最快的,空间效率也是最高的
集合与泛型
//第一段:泛型出现之前的集合定义方式
List al = new ArrayList();
al.add (new Object());
al.add (new Integer(111));
al.add(new String("hello alal"));
//第二段:把a1引用赋值给a2,注意a2与al的区别是增加了泛型限制<object>
List<Object> a2 = al;
a2.add (new Object());
a2.add (new Integer(222));
a2.add(new String("hello a2a2"));
//第三段:把a1引用赋值给a3,注意a3与al的区别是增加了泛型<Integer>
List<Integer> a3 = al;
a3.add(new Integer (333));
下方两行编译出错,不允许增加非Integer类型进入集合
a3.add(new object());
a3.add(new String("hello a3a3"));
//第四段:把a1引用赋值给a4,al与a4的区别是增加了通配符
List<?>a4 = al;
//允许副除和清除元素
al.remove(O);
a4.clear();
// 编译出错。不允许增加任何元素
a4.add (new Object());
<? extends T> put功能受限 ?只能是T及T的子类型
<? super T> get 功能受限 ?只能是T及T的父类型
元素的比较
Comparable和Comparator两个接口的区别:
- Comparable:自己与别人比较
- Comparator:第三方比较两个对象
hashCode 与 equals
通过哈希将数据分散开来
- equals相等 则hashCode必须相等
- 覆写equals 必须覆写hashCode
// HashMap 判断两个key是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
快速失败机制
当前线程维护一个expectedModCount 遍历之前这个值等于modCount
如果在遍历的过程中发现 expectedModCount != modCount 就代表集合被别的线程修改了 这时候会跑出一个ConcurrentModificationException
这个时候得使用迭代器来实现在遍历中修改集合的功能
并发集合都是使用快速失败机制实现的 集合修改与遍历没有任何关系 但这种机制会导致读取不到最新的数据 也是CAP理论中 A与P的矛盾
注意事项
线程安全
Collections 帮我们实现了 List、Set、Map 对应的线程安全的方法
synchronized打头的方法可以将指定的集合包装成线程安全的集合
集合性能
- 批量新增
在 List 和 Map 大量数据新增的时候,我们不要使用 for 循环 + add/put 方法新增,这样子会有很大的扩容成本,我们应该尽量使用 addAll 和 putAll 方法进行新增
- 批量删除
ArrayList的remove方法,删除之后都会对被删除位置的元素进行移动,如果进行循环remove,会造成性能问题,可以采用removeAll方法,这个批量删除接口只会对数组的元素移动一次
集合的坑
- Arrays.asList(array),当array被修改时,会造成list也被修改
- toArray 方法如果声明的数组小于list长度,会得到一个空数组
JAVA7到JAVA8集合的升级
- 所有集合都新增了forEach 方法
- JAVA7中ArrayList无参初始化是直接初始化10,JAVA8无参初始化则是一个空数组
- JAVA7中的HashMap无参初始化的大小是16,JAVA8无参初始化则是一个空数组,并且引入了红黑树,并且增加了xxIfAbsent等方法
- Arrays 提供了很多 parallel 开头的方法,这些方法支持并行计算
Guava
工厂模式初始化
HashMap<Object, Object> map = Maps.newHashMap();
Lists
ArrayList<String> list = Lists.newArrayList();
ArrayList<Object> objects = Lists.newArrayListWithCapacity(10);
// 不知道精确值,给出一个模糊值
ArrayList<Object> objects1 = Lists.newArrayListWithExpectedSize(20);
// 反转一个list,并非物理反转,而是通过对传入index的处理实现的
var list = Lists.reverse(list)
// list拆分
var list = Lists.partition(list,3)